I forbindelse med avvikling av Datahotellet er det mange som har spørsmål om alternativa til å slå opp i ELMA sitt datasett over mottakarar på Datahotellet. Her gir vi ei oversikt og nokre peikarar til korleis bruke alternativa.
Det er to alternativ: PEPPOL Directory og PEPPOL-oppslag via SML+SMP.
Med desse to alternativa kan ein slå opp informasjon om ein mottakar i Peppol og kva dokumenttypar den kan motta.
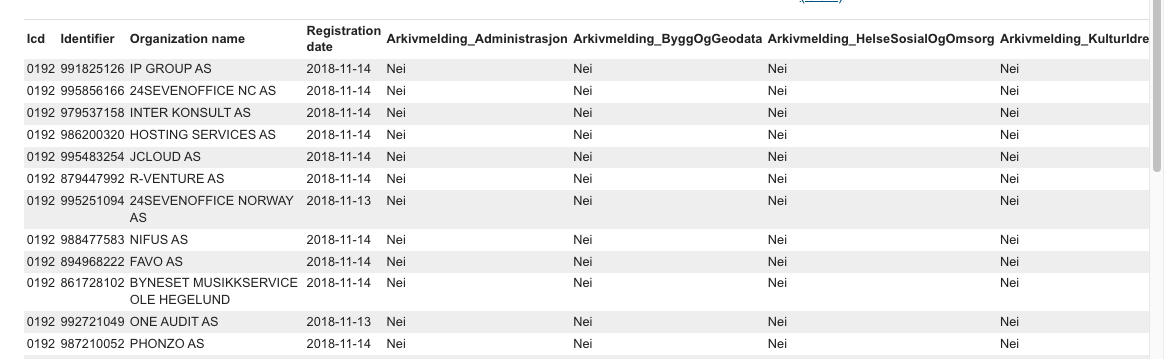
Skjermbilde av datasettet difi/elma/participants på Datahotellet, vist via web-grensesnittet på hotell.difi.no
Bakgrunn
ELMA-datasettet inneheld liste over alle mottakarar registrert i ELMA og viser kva dokumenttypar den enkelte verksemd kan motta. Typisk har dette blitt brukt til å slå opp på organisasjonsnummer for å sjekke om ei verksemd kan motta EHF-faktura for å avgjere om ein skal sende faktura som EHF-faktura eller på annan måte som e-post.
Kva er PEPPOL og ELMA, eigentleg?
PEPPOL er ein organisasjon som gjer det mogeleg at forretningsdokument, til dømes fakturaer, flyt mellom organisasjonar.
Digitaliseringsdirektoratet (Digdir) utviklar og driftar ELMA, mens Direktoratet for forvaltning og økonomistyring (DFØ) er Peppol-myndighet i Norge.
Vi går ikkje inn på detaljane i Peppol her, og avgrensar oss til å forklare litt som er relevant:
- Elektronisk mottakaradresseregister (ELMA) er eit norsk register over foretak som tar i mot dokumentformat innan eit av Peppol-domenene. ELMA er ein SMP. Dei fleste norske verksemder er registrert i Elma, men norske verksemder kan vere registrerte i andre SMP-ar. Les meir om ELMA på samarbeid.digdir.no
- Service Metadata Provider (SMP) er eit register over mottakarar. Ein mottakar i Peppol kan berre vere knytt til ein SMP.
- Service Metadata Locator (SML) er tenesta som sørger for at oppslag på ein mottakar kjem fram til rett SMP utan at ein på førehand veit kva SMP ein mottakar tilhøyrer.
PEPPOL Directory
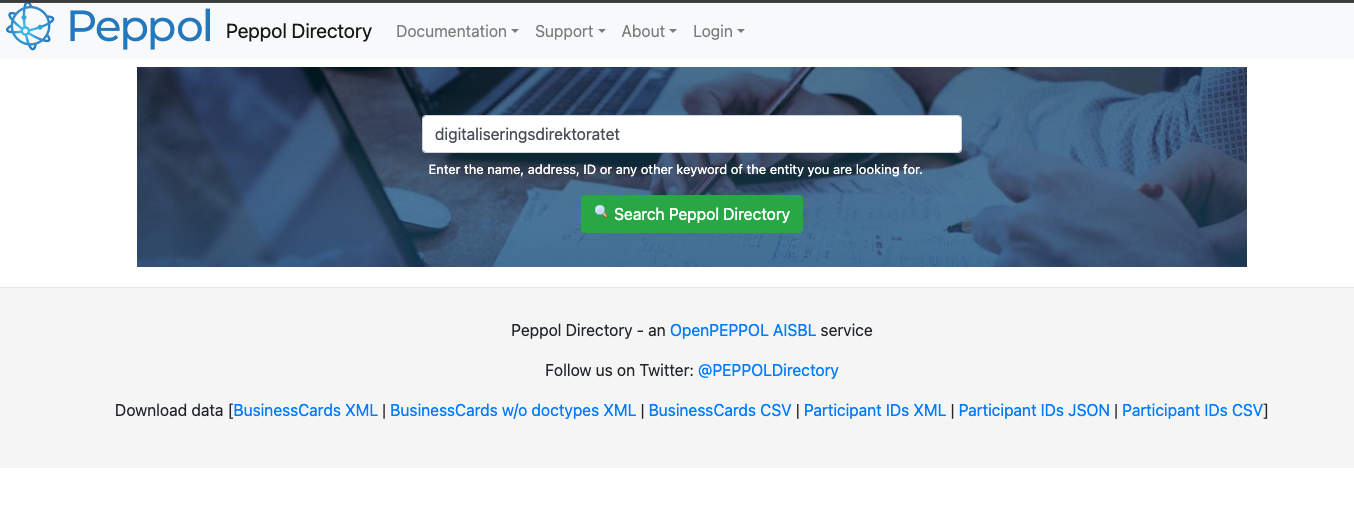
Skjermbilde: framsida av directory.peppol.eu
PEPPOL Directory har eit API der ein kan slå opp på organisasjonsnummer, søke på namn og laste ned komplett datasett.
Elma eksporterer alle sine mottakarar til PEPPOL Directory. Merk at det ikkje er påbudt for SMP-ar å registrere mottakarar i PEPPOL Directory. Difor anbefaler vi å bruke PEPPOL-oppslag med mindre du skal slå opp svært mange mottakarar samtidig.
Eksempel på å slå opp Digdir. 0192 er landkode for Norge.
https://directory.peppol.eu/search/1.0/json?participant=iso6523-actorid-upis::0192:991825827
Så får ein følgande svar:
{
"version": "1.0",
"total-result-count": 1,
"used-result-count": 1,
"result-page-index": 0,
"result-page-count": 20,
"first-result-index": 0,
"last-result-index": 0,
"query-terms": "participant=iso6523-actorid-upis::0192:991825827",
"creation-dt": "2024-10-25T05:26:05.427Z",
"matches": [
{
"participantID": {
"scheme": "iso6523-actorid-upis",
"value": "0192:991825827"
},
"docTypes": [
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:eformidling:xsd::feil"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:leveringskvittering::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:flyttet::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:arkivmelding:xsd::arkivmelding"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:varslingfeiletkvittering::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:returpostkvittering::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:einnsyn:xsd::einnsyn_kvittering"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:eformidling:xsd::status"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:feil::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:einnsyn:xsd::innsynskrav"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:aapningskvittering::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:einnsyn:xsd::publisering"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:digital::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:utskrift::1.0"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:oasis:names:specification:ubl:schema:xsd:CreditNote-2::CreditNote##urn:cen.eu:en16931:2017#compliant#urn:fdc:peppol.eu:2017:poacc:billing:3.0::2.1"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:no:difi:arkivmelding:xsd::arkivmelding_kvittering"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:oasis:names:specification:ubl:schema:xsd:Invoice-2::Invoice##urn:cen.eu:en16931:2017#compliant#urn:fdc:peppol.eu:2017:poacc:billing:3.0::2.1"
},
{
"scheme": "busdox-docid-qns",
"value": "urn:fdc:digdir.no:2020:innbyggerpost:xsd::innbyggerpost##urn:fdc:digdir.no:2020:innbyggerpost:schema:mottakskvittering::1.0"
}
],
"entities": [
{
"name": [
{
"name": "DIGITALISERINGSDIREKTORATET"
}
],
"countryCode": "NO",
"websites": [
"www.digdir.no"
],
"regDate": "2019-03-29"
}
]
}
]
}
PEPPOL-oppslag
Dette er måten oppslag vert gjort på i sjølve Peppol-nettverket. Ein slår opp ein mottakar om gangen, på organisasjonsnummer. Oppslag brukar DNS og subdomener.
Vi anbefaler å gjere desse oppslaga ved behov — ikkje køyre store batch-jobbar for å synkronisere eigne register — for å unngå unødig trafikk. For oppslag av mange mottakarar samtidig, bør du bruke Peppol Directory.
Eksempel der vi slår opp Digdir (org.nr. 991825827)
Først må ein generere URL. Det er forklart på helger.com. Dersom mottakaren finst i Peppol, vil URL-en peike til SMP-en mottakaren er registrert hos.
http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu
I dette tilfellet peikar URL til ELMA.
For å slå opp kva dokumenttypar som er støtta, må ein legge til mottakar-id i URL-en:
http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis::0192:991825827
Respons:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<ns2:ServiceGroup xmlns="http://busdox.org/transport/identifiers/1.0/" xmlns:ns2="http://busdox.org/serviceMetadata/publishing/1.0/" xmlns:ns3="http://www.w3.org/2005/08/addressing" xmlns:ns4="http://www.w3.org/2000/09/xmldsig#">
<ParticipantIdentifier scheme="iso6523-actorid-upis">0192:991825827</ParticipantIdentifier>
<ns2:ServiceMetadataReferenceCollection>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aeformidling%3Axsd%3A%3Afeil"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Aleveringskvittering%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Aflyttet%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aarkivmelding%3Axsd%3A%3Aarkivmelding"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Avarslingfeiletkvittering%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Areturpostkvittering%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aeinnsyn%3Axsd%3A%3Aeinnsyn_kvittering"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aeformidling%3Axsd%3A%3Astatus"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Afeil%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aeinnsyn%3Axsd%3A%3Ainnsynskrav"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Aaapningskvittering%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aeinnsyn%3Axsd%3A%3Apublisering"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Adigital%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Autskrift%3A%3A1.0"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Aoasis%3Anames%3Aspecification%3Aubl%3Aschema%3Axsd%3ACreditNote-2%3A%3ACreditNote%23%23urn%3Acen.eu%3Aen16931%3A2017%23compliant%23urn%3Afdc%3Apeppol.eu%3A2017%3Apoacc%3Abilling%3A3.0%3A%3A2.1"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Ano%3Adifi%3Aarkivmelding%3Axsd%3A%3Aarkivmelding_kvittering"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Aoasis%3Anames%3Aspecification%3Aubl%3Aschema%3Axsd%3AInvoice-2%3A%3AInvoice%23%23urn%3Acen.eu%3Aen16931%3A2017%23compliant%23urn%3Afdc%3Apeppol.eu%3A2017%3Apoacc%3Abilling%3A3.0%3A%3A2.1"/>
<ns2:ServiceMetadataReference href="http://b-9823154777831486f5f30f7f41385a2a.iso6523-actorid-upis.edelivery.tech.ec.europa.eu/iso6523-actorid-upis%3A%3A0192%3A991825827/services/busdox-docid-qns%3A%3Aurn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Axsd%3A%3Ainnbyggerpost%23%23urn%3Afdc%3Adigdir.no%3A2020%3Ainnbyggerpost%3Aschema%3Amottakskvittering%3A%3A1.0"/>
</ns2:ServiceMetadataReferenceCollection>
</ns2:ServiceGroup>
Ut frå responsen kan ein så tolke svaret mot eigen forretningslogikk — til dømes avgjere om ein mottakar støttar EHF-faktura.
Sjå biblioteket vefa-peppol lookup for Java-implementasjon.
Lenker

")